Spark
Spark is built after MapReduce. It has several advantages.
-
API is more friendly for developers.
-
It uses RAM for calculating.
-
It has more calculation stage.
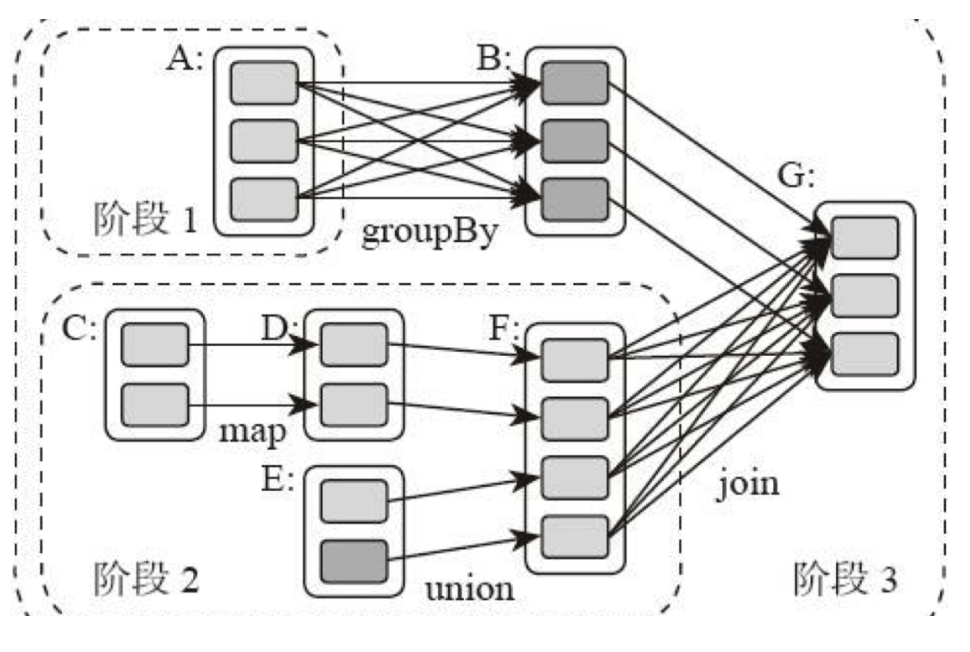
Spark's core is RDD (Resilient Distributed Dataset).
RDD has 2 kinds of functions:
-
action:
count,saveAsTextFile, etc -
transformation:
map,filter,reduceByKeyTransformation can be classified by whether applying
shuffle.mapdoesn't shuffle, therefore it doesn't create new RDD. It's fast. However,reduceByKeyneeds shuffling. It creates new RDD, and it costs time.